
Introduction
One of the key concerns when it comes to NFV is around performance, and that the network function you are virtualizing can deliver that of its hardware counterpart. However, with all the vendors competing to ensure their hardware based platforms are the fastest, through a range of dedicated based hardware, such as ASICs, FPGAs, crypto engines and SSL accelerators - can a virtualized instance really compete?
Within this section we will look at the various system optimization techniques and technologies available within the industry that can be used to enhance the performance of a virtual network function.
NUMA
Traditionally within a Symmetric Multiprocessor (SMP) machine, all CPUs within the system access the same memory. However, as CPU technologies have evolved and the performance of CPUs increased, so did the load upon the memory bus and the amount of time the CPU needs to wait for the data to arrive from memory.
NUMA (Non-Uniform Memory Access) addresses this by dividing the memory into multiple memory nodes (or cells), which are "local" to one or more CPUs.[1]
NUMA nodes are connected together via an interconnect, so all CPUs can still access all memory. While the memory bandwidth of the interconnect is typically faster than that of an individual node, it can still be overwhelmed by concurrent cross node traffic from many nodes.[2] So, though NUMA allows for faster memory access for CPUs accessing local memory nodes, access to remote memory nodes (via the interconnect) is slower, and here lies the need for NUMA topology awareness.
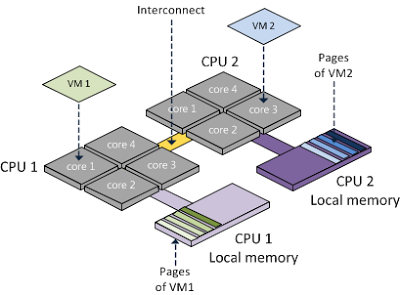
Figure 1 - NUMA based Memory Nodes.[3]
CPU Pinning
When the hypervisor virtualizes a guest's vCPU, it is typically scheduled across any of the cores within the system. Of course, this behaviour can lead to sub-optimal cache performance as virtual CPUs are scheduled between CPU cores within a NUMA node or worse, between NUMA nodes.[4] CPU pinning provides the ability to restrict which physical CPUs the virtual CPUs run on, in turn resulting in faster memory read and writes from the CPU.
Huge Paging
Within a system, processes work with virtual memory, also known as pages. The virtual memory is mapped to physical memory, and the mapping is stored within a data structure called a page table.
Each time a process accesses memory, a kernel translates the desired virtual memory address to a physical one by looking[5] into this page table. However, the page table is pretty complex and slow and we simply can't parse the entire data structure every time some process accesses the memory.[6] Thankfully, CPUs contain hardware cache called the TLB (Translation Lookaside Buffer), which caches physical-to-virtual page mappings, speeding up lookups. However, the capacity of the TLB is limited; this is where huge pages come in. By increasing the size of the page, a larger amount of memory can be mapped within the TLB, reducing cache misses, and speeding up memory access times.
Let's look at a simple example. Our example is based on the TLB having 512 entries.
| Page Size | TLB Entries | Map Size | Example | |
|---|---|---|---|---|
| Without Hugepages | 4096b | 512 | 2MB | 4096b * 512 = 2MB |
| With Hugepages | 2MB | 512 | 1GB | 2MB * 512 = 1GB |
Table 1 - Huge Page Example.
References
"CPU Pinning and NUMA Awareness in OpenStack - Stratoscale." 15 Jun. 2016, https://www.stratoscale.com/blog/openstack/cpu-pinning-and-numa-awareness/. Accessed 22 Aug. 2017. ↩︎
"Driving in the Fast Lane – CPU Pinning and NUMA Topology ...." 5 May. 2015, http://redhatstackblog.redhat.com/2015/05/05/cpu-pinning-and-numa-topology-awareness-in-openstack-compute/. Accessed 24 Aug. 2017. ↩︎
"OpenStack in Production: NUMA and CPU Pinning in High ...." 3 Aug. 2015, http://openstack-in-production.blogspot.co.uk/2015/08/numa-and-cpu-pinning-in-high-throughput.html. Accessed 21 Aug. 2017. ↩︎
"TripleO, NUMA and vCPU Pinning: Improving Guest ... - StackHPC Ltd." 3 Feb. 2017, https://www.stackhpc.com/tripleo-numa-vcpu-pinning.html. Accessed 24 Aug. 2017. ↩︎
"Mirantis OpenStack 7.0 NFVI Deployment Guide: Huge pages." 25 Jan. 2016, https://www.mirantis.com/blog/mirantis-openstack-7-0-nfvi-deployment-guide-huge-pages/. Accessed 24 Aug. 2017. ↩︎
"Advantages and disadvantages of hugepages – TechOverflow." 18 Feb. 2017, https://techoverflow.net/2017/02/18/advantages-and-disadvantages-of-hugepages/. Accessed 24 Aug. 2017. ↩︎