
Introduction
Within this article we will look at some of the issues around the native (i.e no SR-IOV, DPDK etc) Linux datapath when moving a packet through a system, from NIC to a virtual instance. We will do so by tracing the path of a packet through the system.
Our example will be based on a system using Linux Bridge as the vswitch. The hypervisor and Linux Bridge runs within kernel mode, with the virtual machine running within user mode.
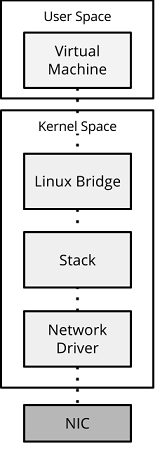
Figure 1 - Standard data path.
Lets begin ...
NIC to Linux Bridge
A frame is received by the NIC. It is moved directly into pre-allocated RX system memory buffers via DMA (Direct Memory Access). The NIC issues an interrupt request to the CPU, requesting the frame is moved from the RX memory buffer into the kernel stack. This is performed by the kernel driver.
Unfortunately hardware interrupts -- in terms of CPU usage -- are expensive ; they alert the CPU to a high-priority condition requiring the processor to suspend what it is currently doing, saving its state, and then initializing an interrupt handler to deal with the event.
Once the frame is within the kernel, it is processed through the network stack up to the Linux Bridge. However, the kernel network stack is inherently slow. It has to deal with a number of functions and protocols, from ARP to VXLAN, and it has to do it all securely.[1]
Linux Bridge to Virtual Instance
Once the frame has been received by the Linux bridge, and the necessary operations performed in order to determine that the packet is destined for our virtual machine, the kernel performs a system call.
The system call initiates a context switch. This switches the CPU to operate in a different address space. This allows our virtual instance, which is running within userspace, to 'context switch' to kernel space and retrieve the frame before returning to userspace so that it can further process the frame. Of course, this is hugely inefficient - in order to retrieve the pack, the virtual instance has to stop what it is doing for each IO request, not to mention the cost /overhead involved to perform the actual copying of data (/frame) between the two different address spaces.
Even though this flow has been hugely simplified, it highlights the following:
moving a frame through the kernel data-path and between system memory spaces is computationally expensive.
Conclusion
As you can see, out of the box the Linux network stack has various short comings when it comes to effiently passing the traffic from the NIC to userspace.
This is, of course, asabated when high work traffic workloads are introduced, in the case of NFV.
However, there are a range of technologies that address these issues. Ranging from kernel bypassing (DPDK), direct passthroughs (SRIOV) to memory/CPU optimizations (CPU Pinning, Huge Pages).
References
"Pushing the Limits of Kernel Networking - Red Hat Enterprise Linux Blog." 29 Sep. 2015, http://rhelblog.redhat.com/2015/09/29/pushing-the-limits-of-kernel-networking/. Accessed 22 Aug. 2017. ↩︎